





王洪平
摘 要 试验提出了一种最小二乘支持向量机的猪血发酵制备小肽的水解度预测新模型。以接种量、发酵温度、发酵时间三个工艺参数为输入,水解度为输出,通过正交试验获得数据样本。以试验数据为基础,建立最小二乘支持向量机模型,利用模型预测猪血发酵制备小肽的水解度。该方法具有建模速度快、预测精度高、操作简便等优点,不仅克服了常规的BP预测模型的不足,而且性能优于标准支持向量机预测模型。
关键词 猪血发酵;小肽;水解度;预测模型;最小二乘支持向量机
中图分类号 Q516
猪血一般以血粉的形式添加到饲料中,但因血粉中蛋白质分子量大,动物难以消化,且适口性差。利用微生物产生复合酶的特性进行发酵处理,能有效降解血液中的大分子蛋白质,从中提取功能性小肽,大大提高血粉的消化率,有效利用有限的蛋白质资源。猪血发酵制备小肽的关键是工艺水平控制和生产效率的提高,而科学、可靠地估计猪血发酵制备小肽的水解度,对优化工艺参数设计和提高生产效率具有重要意义。然而在猪血发酵制备小肽过程中,由于水解度与发酵工艺参数呈复杂的非线性关系,传统的预测方法存在精度低、操作复杂、周期长、效率低等缺点,难以满足实际生产的需要。近年来,许多学者将人工神经网络(artificial neural network,ANN)技术运用于预测猪血发酵制备小肽水解度,取得了一定的突破。它具有大规模的并行处理和分布式的信息存储能力、良好的自适应性、自组织性及很强的学习、联想、容错和抗干扰能力,能以任何精度逼近复杂非线性系统,获得较高的预测精度和预测效率,但也存在先天性不足,如建立模型时存在着网络内部单元意义不明确、训练时间长、易陷入局部极值点、外插能力弱、泛化能力低等缺点。支持向量机(Support Vector Machine,SVM)是由统计学习理论发展起来的一种新型学习机器,它以结构风险最小化原理为基础,具有较强的学习泛化能力,特别是对小样本数据的模式识别和函数估计具有出色的学习推广性能,克服了ANN结构依赖设计者经验的缺点,较好解决了高维数、局部极小、小样本等机器学习问题。最小二乘支持向量机(Least Square SVM,LS-SVM)是标准SVM的一种新扩展,它用等式约束代替标准SVM的不等式约束,将二次规划问题转化为线性方程组求解,降低了计算复杂性,具有更快的求解速度和更好的鲁棒性。本文尝试用最小二乘支持向量机估计和预测猪血发酵制备小肽的水解度,取得了较好的效果。
1 猪血发酵制备小肽水解度预测
1.1 材料与方法
1.1.1 主要材料
A32菌株(武汉理工大学生物工程实验室筛选保存);新鲜猪血(武汉肉联厂,屠宰后30 min以内收集的);三氯乙酸(上海山浦化工有限公司,分析纯);其它试剂为实验室常用试剂。
1.1.2 主要仪器与设备
HZQ—C型恒温振荡器(哈尔滨东联电子公司);HPS—280型生化培养箱(哈尔滨东联电子公司);AR2140型电子天平(奥豪斯国际贸易公司);CF16RX 型冷冻离心机(Hitachi Koki公司);凯氏定氮仪(北京瑞利分析仪器公司)。
1.1.3 试验方法
1.1.3.1 蛋白质含量的测定
采用半微量凯氏定氮法。
1.1.3.2 三氯乙酸(TCA)可溶氮的测定
在10 ml猪血发酵液中加入10%三氯乙酸溶液10 ml,混匀后静置30 min,11 000 r/min离心,温度为4 ℃,时间为15 min。采用半微量凯氏定氮法测定上清液中氮的含量。
1.1.3.3 水解度 DH 的测定
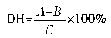
式中:A——猪血发酵后三氯乙酸(TCA)可溶氮含量;
B——猪血发酵前三氯乙酸(TCA)可溶氮含量;
C——猪血发酵前总氮含量。
1.1.4 试验设计
影响猪血发酵法制备小肽产出和分子长度的发酵工艺参数较多,如发酵时间、温度、接种量、起始pH值、装料量等。根据影响程度、现有条件、生产经验,本文选取其中的接种量、发酵温度、发酵时间三个因素为主要影响对象,以水解度DH为发酵制备小肽效果指标,采用二次回归旋转组合设计,试验因素与水平的取值见表1。共设立23个处理组,其中零水平共有9个处理组,不设重复;上下水平处理组每组设 5个重复;其余处理组每组设3个重复,试验设计与结果见表2(其中新鲜猪血N总含量30.07%;新鲜猪血TCA可溶氮含量0.83%)。

1.2 建立LS-SVM模型
以接种量(%)、发酵温度(℃)、发酵时间(h)为输入量,水解度(%)为输出量,建立LS- SVM系统,采用径向基核函数。模型性能评价指标采用平均误差计算公式: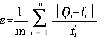
式中:Qi——为实际的测量值;
fi——预测值;
m——验证次数。
核宽度?滓、惩罚系数γ是建立LS-SVM模型的重要问题。?滓和γ的选择通常采用交叉验证方法,但是交叉验证方法由于?滓和γ的参数集参数有限的原因,经常出现不能满足达到误差精度的情况。为此,本文采用一种自适应的?滓和γ选择来建立LS-SVM模型,具体步骤见图1。
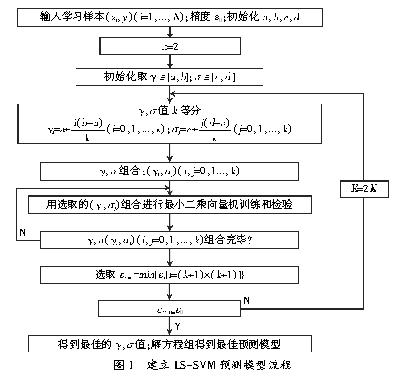
以表2中试验数据的一部分作为训练样本,对系统进行训练,另一部分(3、6、9、12、15、18)留作测试样本对系统进行测试。步骤如下:①输入训练样本;②选定径向基核函数,初始化核宽度?滓和惩罚因子γ;③按自适应选择方法求解核宽度?滓和惩罚因子γ;④根据LS-SVM算法求解回归参数a和b;⑤将模型参数引入LS-SVM预测机,输入测试样本预测水解度。
LS-SVM模型测试结果见表3,最大预测误差小于2.0%,平均误差为1.34%。为了检验本文预测方法与神经网络预测方法的性能,设计一个BP神经网络,网络结构3-8-1。ANN模型预测的结果见表3,最大预测误差大于3%,平均误差为2.87%,这表明本文LS-SVM预测模型精度显著提高,同时,LS-SVM预测模型学习训练时间大大缩短,仅为ANN模型的千分之一。几种预测方法的结果比较见图2。

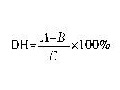
2 结语
在猪血发酵制备小肽生产中,很难用精确的数学模型描述工艺条件与小肽产量之间的复杂关系,从而精确预测水解效果,进行工艺优化和条件改进。人工智能技术预测猪血发酵制备小肽水解度,无须知道各个工艺因素与水解度之间的数学关系公式,为猪血发酵制备小肽生产决策和管理提供了一个新的手段。最小二乘支持向量机由于将求解二次规划问题转化为求解线性方程,是最完善的预测和识别人工智能技术,它不仅适合小样本状态下的机器学习问题,而且性能优于标准SVM和ANN。在建模时间上一般比SVM方法缩短1~2个数量级,比ANN方法可缩短2~3个数量级,而预测精度要比SVM标准模型高0.5~0.6倍,比ANN模型高1~2倍。因此,利用最小二乘支持向量机预测猪血发酵制备小肽效果,具有重要的理论和现实意义。
(参考文献若干篇,刊略,需者可函索)
(编辑:刘敏跃,lm-y@tom.com)
王洪平,武汉理工大学生物与制药工程学院,博士,教授,430074,湖北省武汉市洪山区黄金山路1号。
摘 要 试验提出了一种最小二乘支持向量机的猪血发酵制备小肽的水解度预测新模型。以接种量、发酵温度、发酵时间三个工艺参数为输入,水解度为输出,通过正交试验获得数据样本。以试验数据为基础,建立最小二乘支持向量机模型,利用模型预测猪血发酵制备小肽的水解度。该方法具有建模速度快、预测精度高、操作简便等优点,不仅克服了常规的BP预测模型的不足,而且性能优于标准支持向量机预测模型。
关键词 猪血发酵;小肽;水解度;预测模型;最小二乘支持向量机
中图分类号 Q516
猪血一般以血粉的形式添加到饲料中,但因血粉中蛋白质分子量大,动物难以消化,且适口性差。利用微生物产生复合酶的特性进行发酵处理,能有效降解血液中的大分子蛋白质,从中提取功能性小肽,大大提高血粉的消化率,有效利用有限的蛋白质资源。猪血发酵制备小肽的关键是工艺水平控制和生产效率的提高,而科学、可靠地估计猪血发酵制备小肽的水解度,对优化工艺参数设计和提高生产效率具有重要意义。然而在猪血发酵制备小肽过程中,由于水解度与发酵工艺参数呈复杂的非线性关系,传统的预测方法存在精度低、操作复杂、周期长、效率低等缺点,难以满足实际生产的需要。近年来,许多学者将人工神经网络(artificial neural network,ANN)技术运用于预测猪血发酵制备小肽水解度,取得了一定的突破。它具有大规模的并行处理和分布式的信息存储能力、良好的自适应性、自组织性及很强的学习、联想、容错和抗干扰能力,能以任何精度逼近复杂非线性系统,获得较高的预测精度和预测效率,但也存在先天性不足,如建立模型时存在着网络内部单元意义不明确、训练时间长、易陷入局部极值点、外插能力弱、泛化能力低等缺点。支持向量机(Support Vector Machine,SVM)是由统计学习理论发展起来的一种新型学习机器,它以结构风险最小化原理为基础,具有较强的学习泛化能力,特别是对小样本数据的模式识别和函数估计具有出色的学习推广性能,克服了ANN结构依赖设计者经验的缺点,较好解决了高维数、局部极小、小样本等机器学习问题。最小二乘支持向量机(Least Square SVM,LS-SVM)是标准SVM的一种新扩展,它用等式约束代替标准SVM的不等式约束,将二次规划问题转化为线性方程组求解,降低了计算复杂性,具有更快的求解速度和更好的鲁棒性。本文尝试用最小二乘支持向量机估计和预测猪血发酵制备小肽的水解度,取得了较好的效果。
1 猪血发酵制备小肽水解度预测
1.1 材料与方法
1.1.1 主要材料
A32菌株(武汉理工大学生物工程实验室筛选保存);新鲜猪血(武汉肉联厂,屠宰后30 min以内收集的);三氯乙酸(上海山浦化工有限公司,分析纯);其它试剂为实验室常用试剂。
1.1.2 主要仪器与设备
HZQ—C型恒温振荡器(哈尔滨东联电子公司);HPS—280型生化培养箱(哈尔滨东联电子公司);AR2140型电子天平(奥豪斯国际贸易公司);CF16RX 型冷冻离心机(Hitachi Koki公司);凯氏定氮仪(北京瑞利分析仪器公司)。
1.1.3 试验方法
1.1.3.1 蛋白质含量的测定
采用半微量凯氏定氮法。
1.1.3.2 三氯乙酸(TCA)可溶氮的测定
在10 ml猪血发酵液中加入10%三氯乙酸溶液10 ml,混匀后静置30 min,11 000 r/min离心,温度为4 ℃,时间为15 min。采用半微量凯氏定氮法测定上清液中氮的含量。
1.1.3.3 水解度 DH 的测定
式中:A——猪血发酵后三氯乙酸(TCA)可溶氮含量;
B——猪血发酵前三氯乙酸(TCA)可溶氮含量;
C——猪血发酵前总氮含量。
1.1.4 试验设计
影响猪血发酵法制备小肽产出和分子长度的发酵工艺参数较多,如发酵时间、温度、接种量、起始pH值、装料量等。根据影响程度、现有条件、生产经验,本文选取其中的接种量、发酵温度、发酵时间三个因素为主要影响对象,以水解度DH为发酵制备小肽效果指标,采用二次回归旋转组合设计,试验因素与水平的取值见表1。共设立23个处理组,其中零水平共有9个处理组,不设重复;上下水平处理组每组设 5个重复;其余处理组每组设3个重复,试验设计与结果见表2(其中新鲜猪血N总含量30.07%;新鲜猪血TCA可溶氮含量0.83%)。
1.2 建立LS-SVM模型
以接种量(%)、发酵温度(℃)、发酵时间(h)为输入量,水解度(%)为输出量,建立LS- SVM系统,采用径向基核函数。模型性能评价指标采用平均误差计算公式:
式中:Qi——为实际的测量值;
fi——预测值;
m——验证次数。
核宽度?滓、惩罚系数γ是建立LS-SVM模型的重要问题。?滓和γ的选择通常采用交叉验证方法,但是交叉验证方法由于?滓和γ的参数集参数有限的原因,经常出现不能满足达到误差精度的情况。为此,本文采用一种自适应的?滓和γ选择来建立LS-SVM模型,具体步骤见图1。
以表2中试验数据的一部分作为训练样本,对系统进行训练,另一部分(3、6、9、12、15、18)留作测试样本对系统进行测试。步骤如下:①输入训练样本;②选定径向基核函数,初始化核宽度?滓和惩罚因子γ;③按自适应选择方法求解核宽度?滓和惩罚因子γ;④根据LS-SVM算法求解回归参数a和b;⑤将模型参数引入LS-SVM预测机,输入测试样本预测水解度。
LS-SVM模型测试结果见表3,最大预测误差小于2.0%,平均误差为1.34%。为了检验本文预测方法与神经网络预测方法的性能,设计一个BP神经网络,网络结构3-8-1。ANN模型预测的结果见表3,最大预测误差大于3%,平均误差为2.87%,这表明本文LS-SVM预测模型精度显著提高,同时,LS-SVM预测模型学习训练时间大大缩短,仅为ANN模型的千分之一。几种预测方法的结果比较见图2。
2 结语
在猪血发酵制备小肽生产中,很难用精确的数学模型描述工艺条件与小肽产量之间的复杂关系,从而精确预测水解效果,进行工艺优化和条件改进。人工智能技术预测猪血发酵制备小肽水解度,无须知道各个工艺因素与水解度之间的数学关系公式,为猪血发酵制备小肽生产决策和管理提供了一个新的手段。最小二乘支持向量机由于将求解二次规划问题转化为求解线性方程,是最完善的预测和识别人工智能技术,它不仅适合小样本状态下的机器学习问题,而且性能优于标准SVM和ANN。在建模时间上一般比SVM方法缩短1~2个数量级,比ANN方法可缩短2~3个数量级,而预测精度要比SVM标准模型高0.5~0.6倍,比ANN模型高1~2倍。因此,利用最小二乘支持向量机预测猪血发酵制备小肽效果,具有重要的理论和现实意义。
(参考文献若干篇,刊略,需者可函索)
(编辑:刘敏跃,lm-y@tom.com)
王洪平,武汉理工大学生物与制药工程学院,博士,教授,430074,湖北省武汉市洪山区黄金山路1号。